Epson`s new Voice/Audio single chip MCU solution – S1C31D50
In a lot of applications, the developer spends a lot of time to implement machine to human communication. LEDs or piezo buzzer signals are suitable as simple alerts but for a more complex need of information or alarms often displays are used.
Epson`s Voice/Audio IC S1C31D50 will be a simple solution for complex machine to human communication.
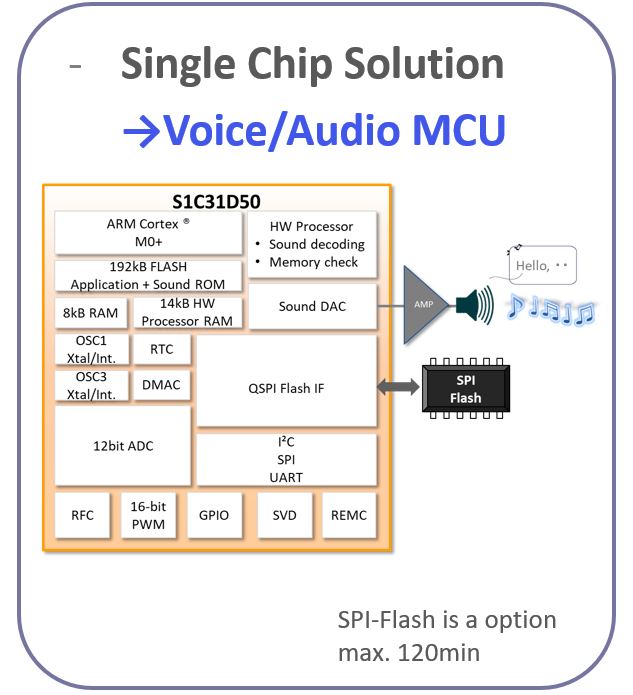
S1C31D50 Key facts
- Cortex-M0+ with 192kB internal Flash for Sound EOV file and application running up to 16Mhz
- Sound HW processor w/ 2-ch mixing & voice speed conversion
- QSPI Flash interface to extend the audio up to 120 min.
- Serial interfaces like SPI, UARTs, I2C & 12 Bit ADC
- Wide VDD range of 1.8V up to 5.5V
Key benefits:
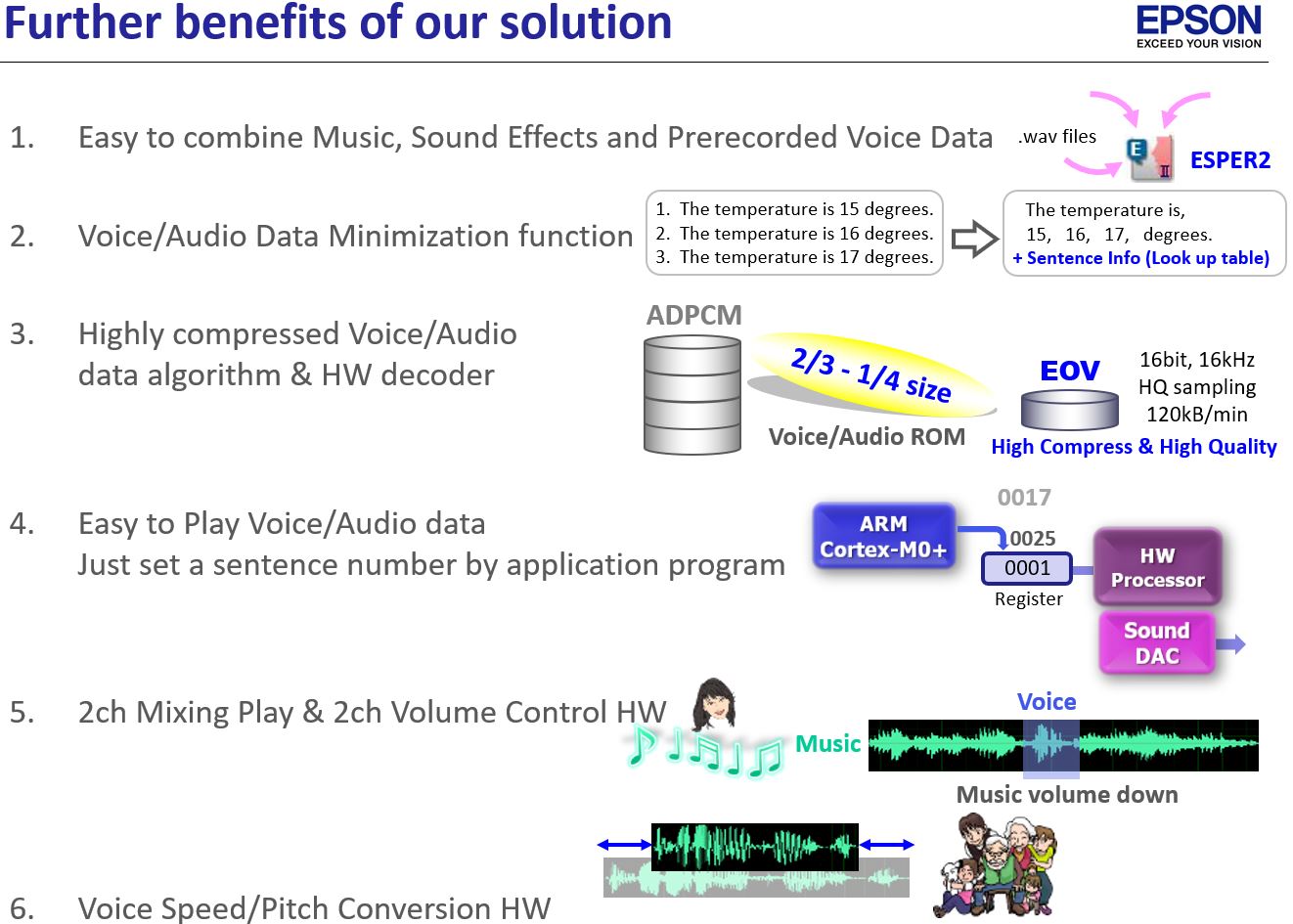
- Easy to combine Music, Sound Effects and Prerecorded Voice Data
- Voice/Audio Data Minimization function
- Highly compressed Voice/Audio data algorithim & HW decoder
- Easy to Play Voice/Audio data
Just set a sentence number by application program
- 2ch Mixing Play & 2ch Volume Control HW
- Voice Speed/Pitch Conversion HW
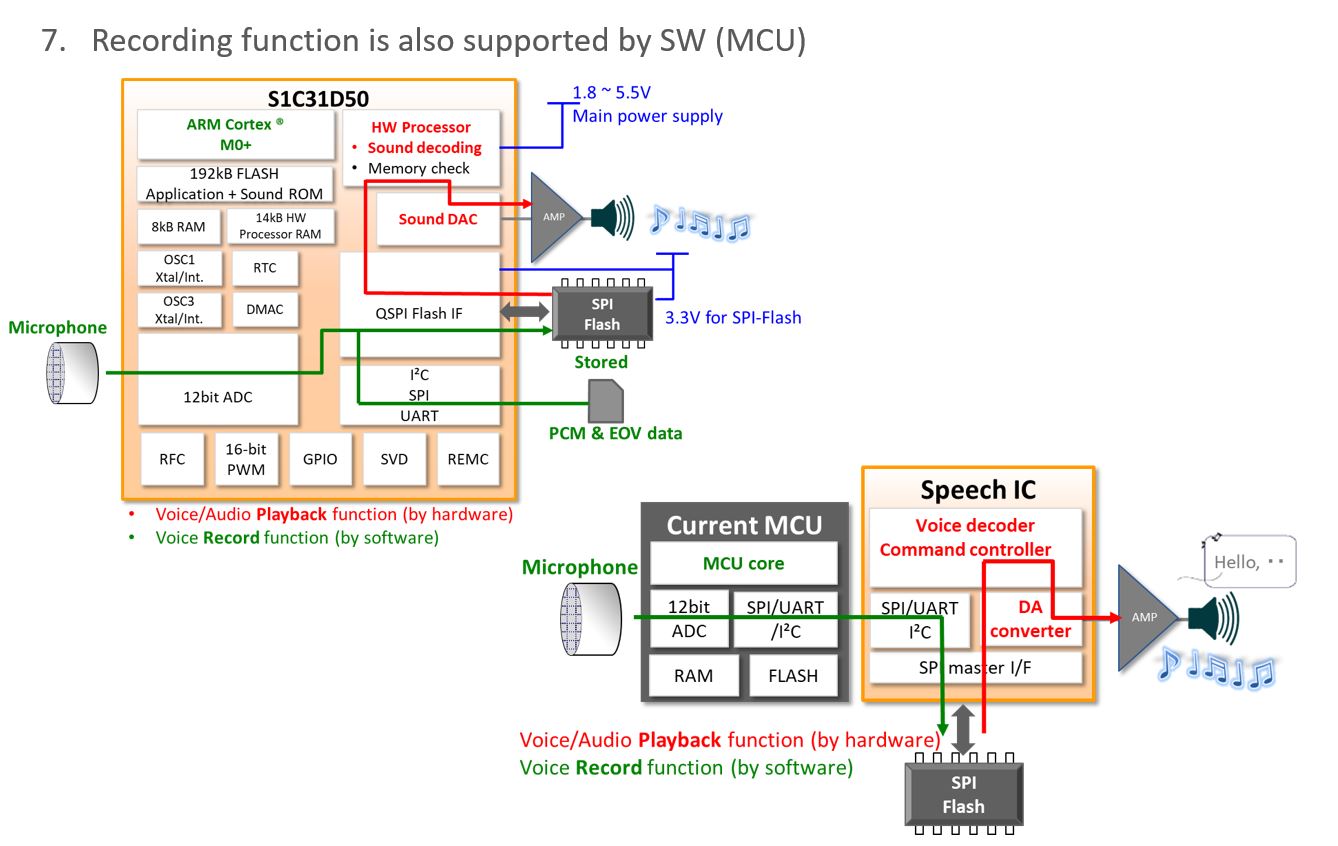
- Recording function is also supported by SW (MCU) – New Way: Epson Voice Creation Tool by PC only compared to Studio recording
- EOV compress voice data 4 Times better than ADPCM
Why not inform the user about current status or alarm in his well-known spoken language?
This might be a question the designer has in mind often but sound production and integration in the application seems just as elaborate as the use of a display.
But now with Epson’s Voice/Audio device tool chain this has become very easy:

Epson gives the developer a simple to use text-to-speech tool (Esper II – free of charge) to generate highly compressed voice data. Decoded by the S1C31D50, a natural sounding and clearly articulated voice becomes audible. An integrated audio hardware processor, DAC and 2 channel mixer makes it easy to connect an amplifier and speaker depending on the needs of the application.
PC Tool Esper II facts
- Guided voice data production process in 4 steps

- German, English, French, Italian, Spanish, Russian & several Asian language support
- Pronunciation fine tune possible
- Only 120kB/min with 16bit Sampling